Beginner friendly reinforcement learning with rlpack

Trained PPO agent playing LunarLander
Lately, I’ve been working on learning more about deep reinforcement learning and decided to start writing my own RL framework as a way to get really familiar with some of the algorithms. In the process, I also thought it could be cool to make my framework a resource for beginners to easily get started with reinforcement learning. With that in mind, the goal wasn’t state of the art performance. However, in the future, I might decide that a high standard of performance is something I want to prioritize over beginner-friendliness.
This framework isn’t finished, but this post indicates the first version of it that I’m happy with being done. Up until now, it’s been the main project I’ve focused on, but moving forward I’ll be putting more time into exploring different things and will more passively work on expanding rlpack. Find the repository here or by clicking on the title of this post.
Algorithms Implemented #
So far, I’ve implemented and tested a couple of policy gradient algorithms.
I haven’t put in the trouble to benchmark these algorithms directly against existing packages, but instead have used performance compared to the Gym leaderboards as a metric of success.
The versions of REINFORCE and A2C implemented are just your vanilla, basic implementations. PPO is implemented with the clipped objective function, AKA PPO-clip.
Performance #
Each of the algorithms here were tested on CartPole-v0, Acrobot-v1, and LunarLander-v2 from OpenAI’s Gym library of RL environments. Below are the reward curves for each environment. Training was stopped when the average reward over the last 100 episodes was over some set threshold. The thresholds were obtained from the Gym leaderboards. CartPole-v0 was considered solved if the last 100 episode average reward was greater than 195, Acrobot-v1 does not have a threshold at which it is considered solved, and LunarLander-v2 is considered solved when the last 100 episode average reward is greater than 200. Here are the reward plots over training.
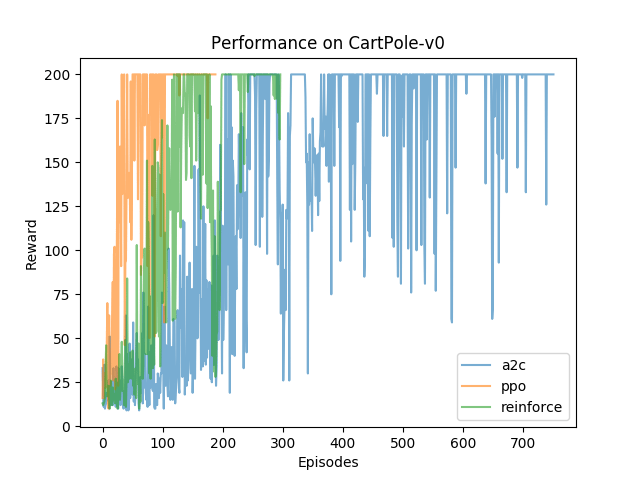
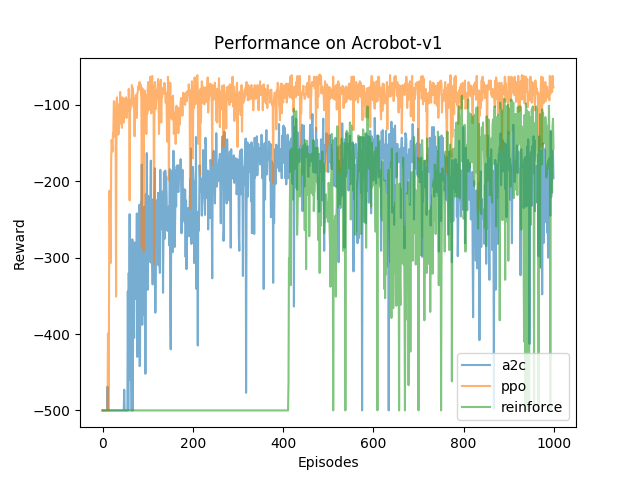
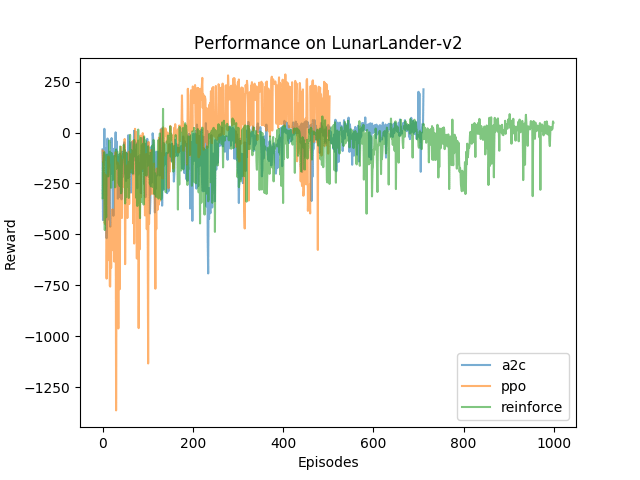
I’ve been pretty impressed by PPO’s performance. For fun, look at the video of PPO playing LunarLander below. The objective here is to control the ship to land in the flags as efficiently as possible. The terrain is also randomly generated. Here, though, the agent tries to land but slides out from between the flags and then is able to make a second attempt to land before the episode ends!

PPO is a very versatile algorithm and is able to obtain good performance on a wide variety of environments. Below is a video of it trying to accomplish the challenging CartPole swingup task, where it aims to swing a pole from beneath a cart and balance it on top of the cart. You can find my implementation of CartPole SwingUp as a Gym environment here.

It does a mediocre job there. Here’s a video of it doing not well at all:

I’ve also got GIFs of REINFORCE playing CartPole and A2C playing Acrobot; have a look here.

REINFORCE playing CartPole-v0. The objective here is to balance the pole on the cart for as long as possible.
A2C playing Acrobot-v1. Here, the goal is to swing the arm up over the line as quickly as possible.
Installation and Usage #
Installation is simple. Head over to my repository on GitHub, open a terminal on your computer, and clone it.
git clone https://github.com/jfpettit/rl-pack.git
pip install -e rl-pack
And you’ve got it installed! If you want to quickly run some code to test it, you can navigate to the /examples/ directory within the rl-pack folder and run the following command:
python [FILE_TO_RUN] --watch --plot --save_mv
The --watch, --plot, and --save_mv tags are optional and indicate whether you’d like to watch your trained agent play in the environment, whether you’d like to see a plot of the agent’s reward over training, and whether you’d like to save an MP4 file of your agent playing in the environment. The [FILE_TO_RUN] is one of reinforce_cartpole.py, a2c_acrobot.py, ppo_lunarlander.py and ppo_swingup.py. If you’d like to run an algorithm on a different environment, you can open one of these prewritten files and modify the environment or you can get more involved and write your own file. Please note, at present this package only supports discrete actions. It is on my to-do list to extend these algorithms to include continuous actions too.
Alternatively, if you’d like to take a departure from the example files and would like to write your own, the example files are still an excellent example of how I intended this package to be used. The idea here was to abstract away the reinforcement learning algorithm and leave it up to the user to define the policy network and the environment. These algorithms should work with any PyTorch neural network and any environment that uses the OpenAI Gym API. However, I haven’t tested recurrent networks so those may or may not work properly with this code.
rlpack requires that your actor-critic networks output both action probabilities and a value estimate. You can implement this by sharing all of the layers except for the output layers of the network or by implementing one actor-critic class that effectively contains two neural networks, one for the policy and one for the value function. It’s all the same to rlpack as long as your forward function returns both action probabilities and a value estimate. Finally, to use your network with rlpack you need to implement an evaluate function within your network class. This function should take in a batch of states and actions and return action log probabilities, value estimates, and distribution entropy for each state and action in the batch. An example of how I’ve done this is in the neural_nets.py file in the repository.
Future work #
For now, I’m going to put less time on rlpack and focus on some other things I find interesting. I will, however, still passively work on things like extending to continuous actions and implementing a couple more algorithms. If you’d like to contribute, feel free to submit a pull request on the repository.
Additional reading. #
If you’re totally brand new to RL and would like a couple of resources to read up on some of the theory behind these things, check out the few links below:
- OpenAI’s SpinningUp
- Sutton and Barto’s Reinforcement Learning: An Introduction
- SpinningUp also has a gigantic list of resources that I’m still using to learn new things too, so I’d recommend checking that out.
Wrapping Up #
If you stuck around this long, thanks. I hope that rlpack is helpful if you choose to use it. If you have any questions you can email me or find me on twitter.
Should someone find this useful in academic work, please cite it using the following:
@misc{Pettitrlpack,
Author = {Pettit, Jacob},
Title = {rlpack},
Year = {2019},
}